Contemporary open-source Large MultiModal Models (LMMs) combined with segmentation decoders (such as LISA) are able to generate awesome segmentation masks but have difficulty on expressions which refer to something that is not present in the image. SESAME, our SEe-SAy-segMEnt LMM, uses joint training to overcome this problem.

We introduce a Novel Problem Setting, requiring LMMs that can See, Say and Segment. Specifically, we require these models to

To facilitate training and evaluation of this new class of models, we introduce a new dataset and benchmark, FP-RefCOCO, FP-RefCOCO+ and FP-RefCOCOg.
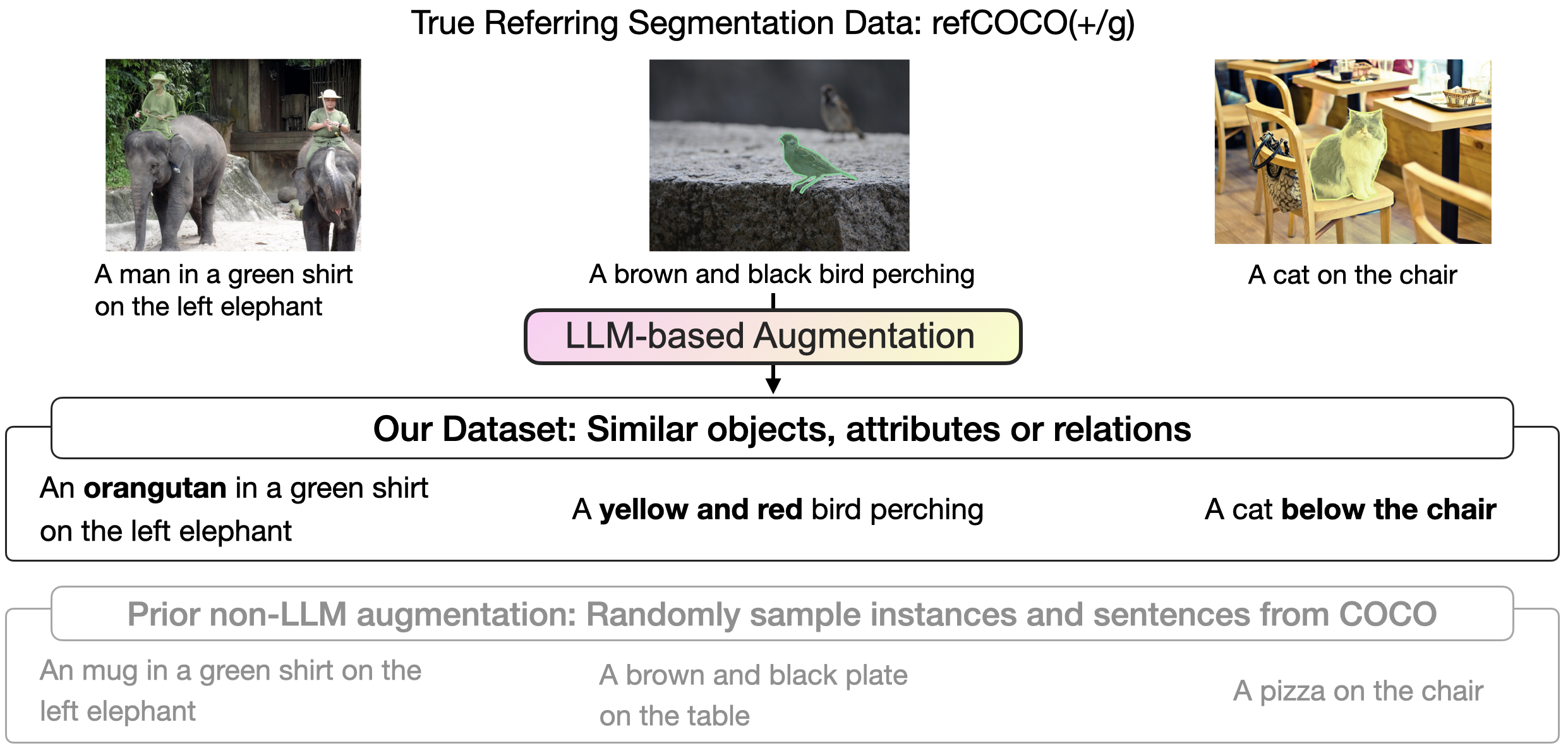
When SESAME is presented with false premises queries with similar objects, attributes, concepts, or activities, it can not only deny these queries but also uses commonsense reasoning to propose relevant alternatives that align with human understanding. For queries that are entirely irrelevant, SESAME will simply reject them without generating any baseless or speculative results.



SESAME is adaptable for complex "reasoning segmentation" tasks, where objects are implicitly implied instead of directly mentioned. By training with specially curated data for false-premise reasoning segmentation, our model can not only dismiss incorrect queries but also optionally suggest an alternative similar concept.



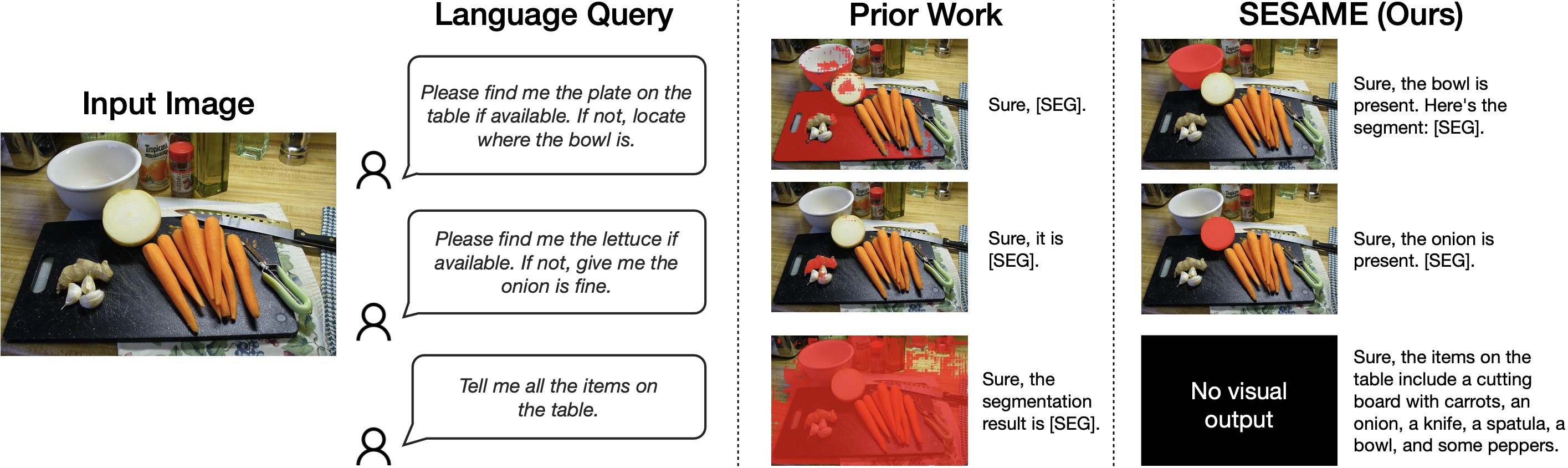
SESAME stands out by processing complex input instructions, including segmenting alternate objects based on conditional queries and conducting basic Visual Question Answering (VQA) without producing segmentation masks. This versatility, unlike prior models like LISA, opens the door for more human-like interactions and the possibility of extending SESAME to multi-round interactions.
@inproceedings{wu2024see,
title={See Say and Segment: Teaching LMMs to Overcome False Premises},
author={Wu, Tsung-Han and Biamby, Giscard and Chan, David and Dunlap, Lisa and Gupta, Ritwik and Wang, Xudong and Gonzalez, Joseph E and Darrell, Trevor},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13459--13469},
year={2024}
}